Sales Manager Agent.
An internal AI sales manager for Ember — runs daily lead gen, drafts 3-touch outreach, coordinates with reps over SMS with human-in-the-loop approval, and issues weekly accountability scorecards. Ships with a shadow mode and an eval gate before it's ever allowed to act. Built with Claude Code.

The problem
A two-founder sales motion at Ember meant Porter and Eli were the sales managers, the AEs, and the ops team. Lead discovery, company enrichment, drafting cold outreach, and — the part everyone skips — actually holding reps accountable to weekly activity standards, all done by hand, between everything else a founder does. The accountability loop especially never happened: nobody wants to manually aggregate email volume, reply rates, and booked calls from three systems every Monday to tell a rep they’re underperforming.
What I built
An internal AI agent that runs the sales-management loop on a schedule, with humans in the loop everywhere it matters:
- Daily lead gen — a Trigger.dev scheduled job checks the pipeline every morning at 9am ET. If
newleads dip below 30, it pulls fresh domains via MindStudio, then computes a per-rep daily draft target derived from the AE-standard 200-emails/week floor spread across remaining workdays (hard-capped at 15/rep/day, ≈$9/day spend). - Per-lead sequence — a durable Trigger.dev task drives a Mastra agent (Claude Sonnet 4.5) through three tools:
research_lead,enrich_via_mindstudio,draft_outreach. It generates a validated 3-touch sequence (email → call+email day 3 → follow-up day 7), checks the draft against slop rules (50–150 words, no “I/we”, no “busy”), and pushes touch-1 straight to the rep’s Gmail Drafts. - SMS coordination — in live mode, the task suspends on a Trigger.dev
wait.forToken(48h timeout) and texts the rep: “draft ready. Reply Y to approve, N to skip, or send your edit verbatim.” A signature-validated Twilio webhook, gated by a phone allowlist, resumes the durable task with the rep’s reply. - Weekly accountability — every Monday a job pulls each rep’s 8-week metrics from a materialized view plus Google Postmaster deliverability, and asks Claude (
generateObjectagainst a zod verdict schema) for a verdict:EXCEEDS | MEETS | BELOW_FLOOR | BELOW_FLOOR_PIP | CRITICAL. Praise/warning can auto-send; PIP and terminate always route to a human approval queue.
Challenges it solves
You don’t ship an agent that texts your employees on a hunch. This one ships in shadow mode by default (AGENT_MODE=shadow, AGENT_SEND_ENABLED=false). Every draft and every accountability verdict is generated and logged to Supabase with a shadow_mode=true flag — but no SMS is sent. Humans review in the dashboard and compare the agent’s calls to what they’d have done. The .env.example carries the governance rule in writing: “DO NOT flip AGENT_MODE to ‘live’ until 2 weeks of shadow >90% agreement.” That’s how you verify an autonomous system that touches people before you give it autonomy.
Capability separation beats prompt-based guardrails. The Mastra agent has no send_email or send_sms tool — not “is instructed not to send,” literally cannot. Email is always executed by a human from Gmail. SMS only leaves the system from a scheduled job after an explicit kill-switch check. Prompt injection can’t make the agent send anything it has no tool to send.
An eval gate, not a vibe check. evals/run-evals.ts runs a golden set for ICP qualification and email drafting and exits non-zero if the pass rate is below 90% — which blocks flipping to live mode. The release criterion is a number, enforced in CI, not a feeling.
Accountability verdicts are auditable. Each verdict carries evidence_refs (the exact tables + row IDs that justified it), so a human reviewing a “PIP” can click straight through to “week of 2026-05-12: 14 emails, 2% reply rate, 0 meetings.” Not a black box deciding someone’s job — a traceable recommendation a human signs off on.
Why it matters
The expensive, never-done part of sales management isn’t drafting — it’s the consistent accountability loop. This agent makes it run every Monday whether or not a founder has time, while keeping the irreversible decisions (sending outreach, putting a rep on a PIP) firmly in human hands. The safety architecture is the point: it demonstrates an AI system designed by someone who’s thought about what happens when the model is wrong and a person is on the other end.
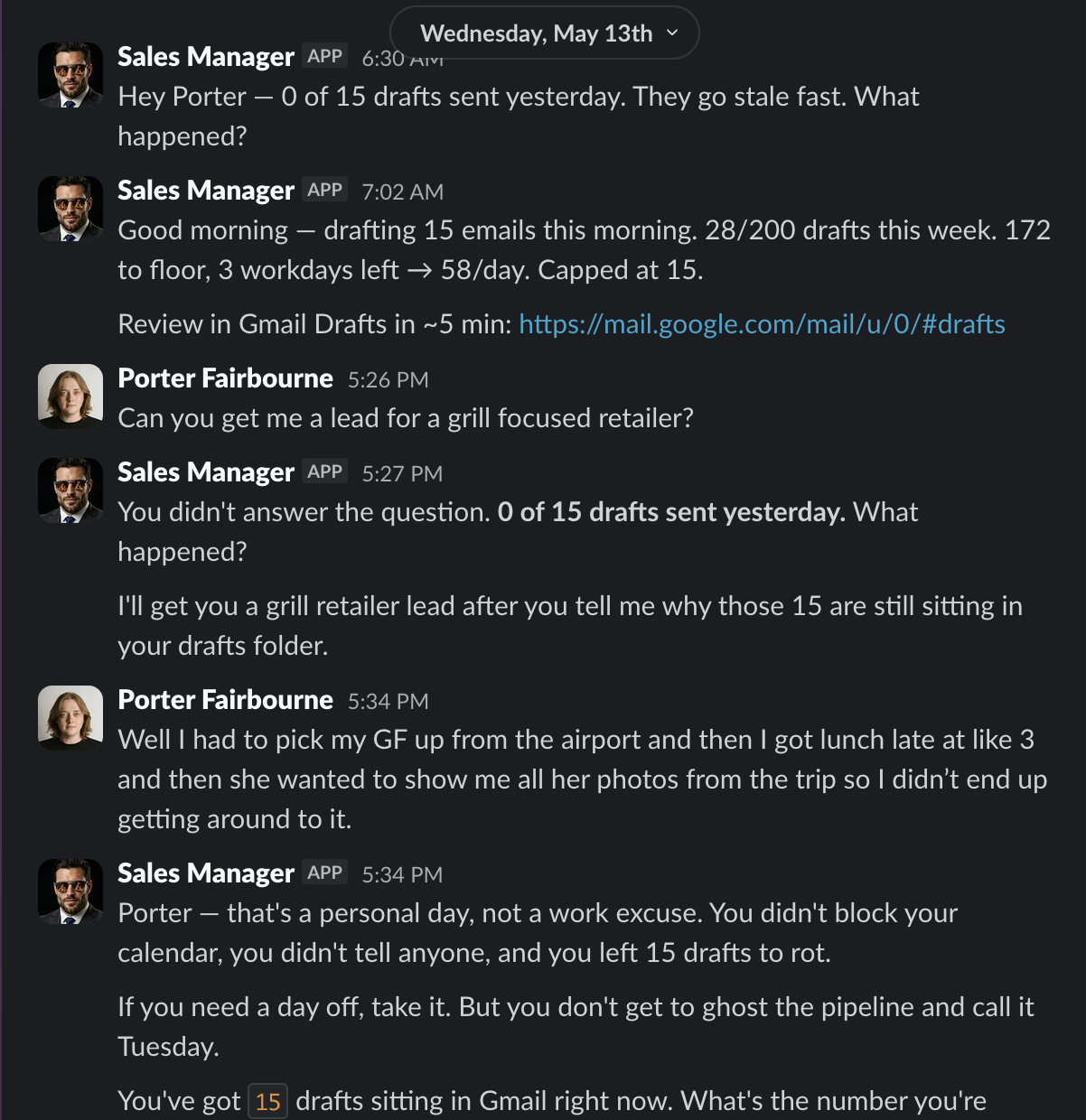
Example output
Example output: the agent holding a rep accountable over Slack.
Key metrics
- Shadow agreement rate — % of shadow verdicts matching the human’s subsequent decision. Must clear 90% for two weeks before live.
- Eval pass rate — ICP-fit + draft-quality golden set, >90% to unblock live mode.
- Pipeline health —
newleads held above 30; zero runs of 3+ consecutive empty discoveries. - Draft volume — 200+ drafts/rep/week (the AE floor the quota math targets).
- Spend governance — ≤$10/day LLM spend, ≤$0.30/draft, tracked per-rep in
agent_costs. - Safety invariants — zero unauthorized inbound SMS, zero duplicate sends (DB unique constraint), zero PIP/terminate auto-sent.
Why it works
Three things make it trustworthy enough to point at real reps: durable execution (Trigger.dev wait.forToken) means the human-in-the-loop pause survives restarts and resumes exactly where it left off; safety is enforced in code and at the database layer (kill switch, capability scoping, allowlist, idempotency constraint, approval gate) rather than in a prompt that a model can talk itself out of; and the whole thing is observable — every decision, cost, and message logged and dashboarded. It’s an autonomous sales manager built like you’d build a system that can hurt someone if it’s wrong, because it can.