SKU Enrichment Agent.
Enriches one SKU into structured JSON with confidence scores and sources.
End of run
One API call in, one Enriched_SKU JSON record out:
{
"coverageScore": 0.44,
"mergedAttributes": { ... },
"discoveredAttributes": { ... },
"missingRequiredAttributes": [ ... ]
}Every value carries the source snippet that justified it, weighted by source type (PDF spec sheet 0.8 > vendor PDP 0.6 > retailer page 0.4). Fan out across thousands of SKUs in parallel and a customer’s half-blank product catalog becomes a structured, audit-ready dataset overnight.
Representative run: nine requested attributes (Universal Code, Category, Length, Width, ASIN, Primary Color, Fabric, Stock Unit, Handle) resolved end-to-end in 89 seconds for $0.03.
Challenges it solves
LLM hallucination on URLs. Discovery is deterministic. Google Search finds real vendor PDPs, retailer pages, and spec PDFs. LLMs only classify which of the returned results is which type. They never guess a URL.
Bot walls. A JavaScript pre-processor detects Cloudflare, Incapsula, and other WAF blocks before they corrupt the extraction pipeline, and the agent silently routes around them to the next candidate source.
Conflicting sources. Vendor PDPs, retailer listings, and PDF spec sheets disagree constantly on basic facts. A weighted merge resolves conflicts by source authority and per-attribute confidence, the highest-weighted confident value wins, and the losing values are kept in the evidence log.
Cost at catalog scale. Heavy lifting (HTML cleaning, content assembly, output formatting) runs in JavaScript. LLMs only do the work LLMs are good at: classification and structured extraction. Net cost: $0.03 per SKU.
Catalog-scale orchestration. No internal loops. Each invocation processes exactly one SKU, so the agent is trivially parallel. Fan it out from Make.com, Zapier, the MindStudio NPM package, or a raw webhook POST.
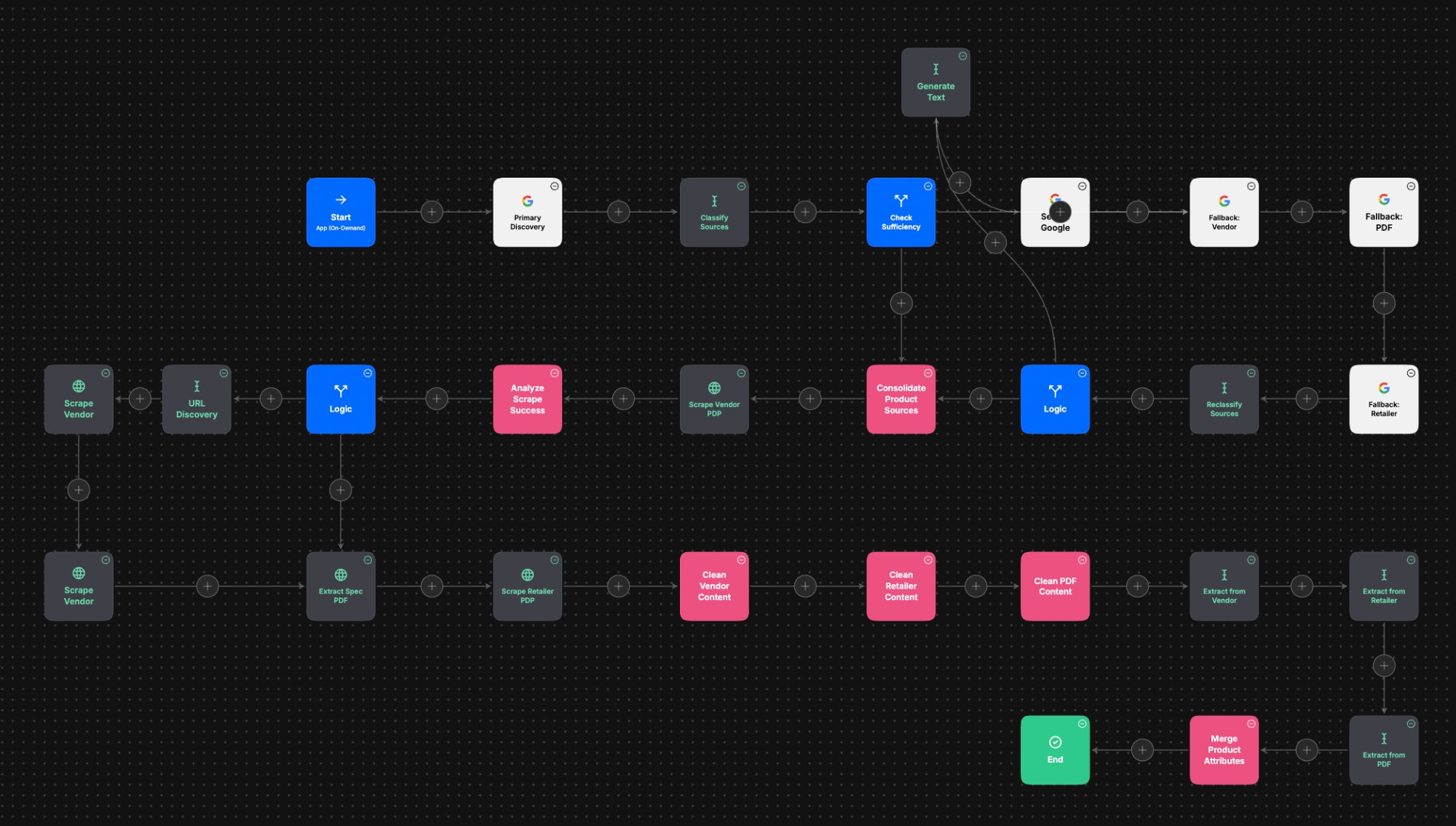
Under the hood
Main.flow runs four phases: discovery (primary + three fallback
Google queries), scraping (up to three sources), per-source
attribute extraction, and weighted merge into the final assembly.
Four models, picked per job: GPT-4o Mini classifies search results, Gemini 2.5 Pro reads PDFs, Claude 4.5 Haiku handles cleaning, Claude 4.6 Sonnet does the structured extraction.