Zero to a populated catalog in one conversation.
Production conversational agent that takes a new supplier from signup to a fully populated catalog in one session — Firecrawl-driven company discovery, a three-stage AI field-matching pipeline, streaming progress updates, retry-hardened Claude calls, and a graduation flow that flips the user to admin. Auto-activated for every new tenant on day one.
The problem
New PIM customers churn during setup. The old way looks like this: a sales engineer schedules an onboarding call. The customer sends a CSV. Someone on the vendor side hand-maps columns to internal fields. The customer gets a Loom of how to invite their team. Two weeks later, half the customers haven’t logged back in.
Industrial PIMs sell six- and seven-figure contracts and still treat onboarding as a services engagement. That’s an enormous tax on a product that’s supposed to remove tax from product data work. The Onboarding Agent eats that engagement.
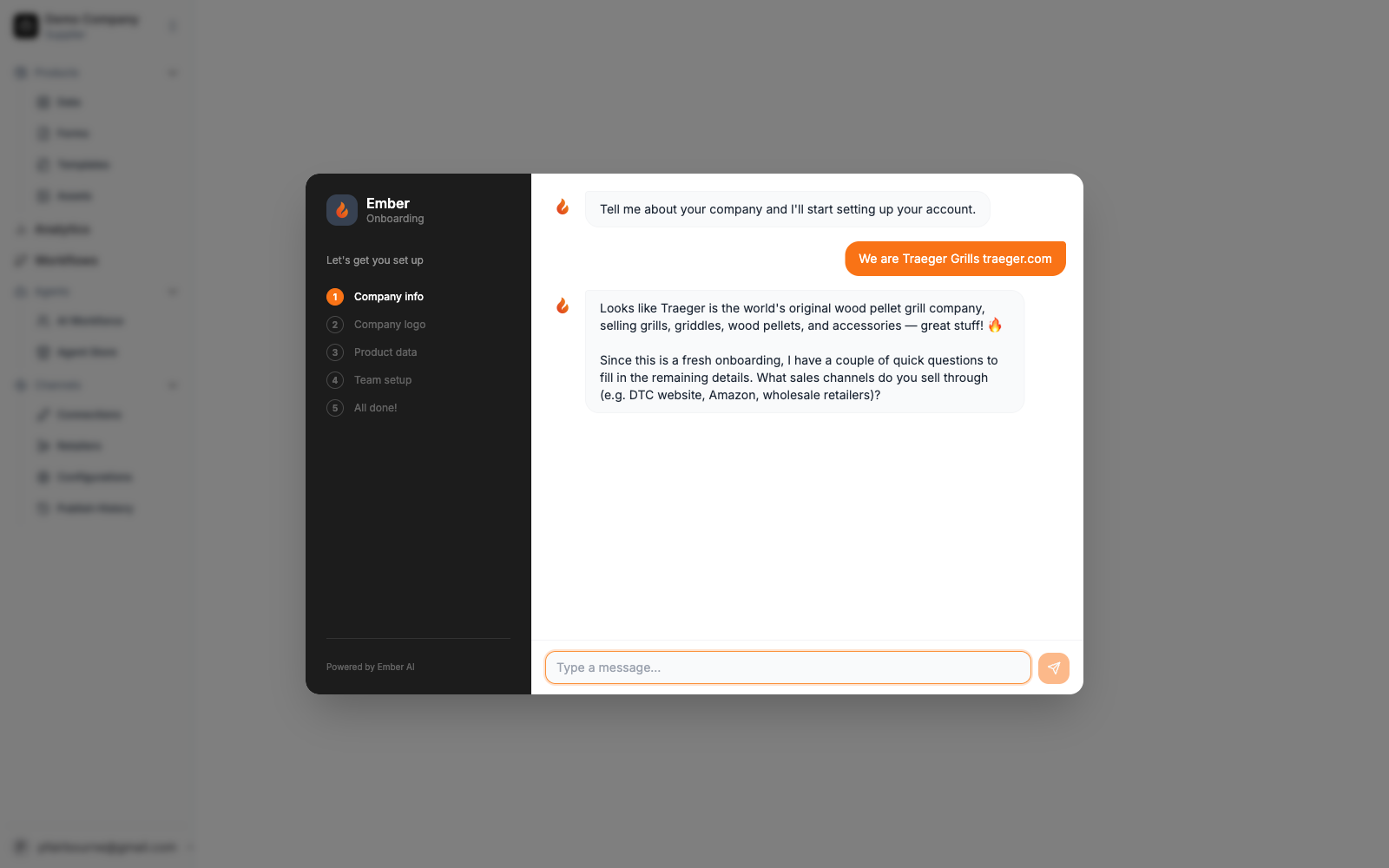
What ships when an onboarding session ends
In one ~15-minute conversation, a brand-new supplier finishes with:
- Their company profile populated automatically (name, industry, products, SKU count, distribution channels, common data challenges) — pulled by Firecrawl from their public website, structured by Claude, and saved to the
companiestable. - A logo uploaded to Supabase Storage.
- A data template built from the supplier’s first CSV. Every column from the CSV is matched to a standard field, with confidence scores, and saved as a reusable template the next upload reuses verbatim.
- A team with invitations sent.
- Their admin role assigned, the company flagged
is_onboarded = true, and the user dropped into the live product on their first dashboard view.
Zero phone calls. Zero email handoffs. Zero “we’ll need to schedule a follow-up.” The agent does what a services team would do — except it does it on the user’s first session, and it never costs a salary.
What I built
A conversational agent at /api/agent/onboarding, backed by Claude Sonnet 4.6 (8192 tokens, temperature 0.4), with eleven active tools wired into a six-stage flow:
- STATUS CHECK — pulls the company’s current onboarding state from
company_agent_activations, template count, team count, pending invites. Decides which stage to resume. - DISCOVER — asks for the company’s URL. Calls Firecrawl with markdown extraction + scroll actions, trims the response to 8,000 chars, and asks Claude to structure the page into name/industry/SKU count/sales channels. Persists via
update_company_info. - LOGO — requests an image upload via a UI-side widget.
save_company_logowrites to Supabase Storage and thecompanies.logofield. - DATA IMPORT — accepts a CSV upload, runs the three-stage field-matching pipeline (described below), surfaces a confirm-mapping widget in the chat, and writes a reusable
data_template+data_template_mappingsonce the user confirms. - TEAM — creates teams via
create_team, sends invitations viainvite_team_member. - WRAP-UP — calls
mark_onboarding_complete, flipscompanies.is_onboarded, and promotes the user torole_id = 1(Admin).
The conversation streams via NDJSON over a native ReadableStream: every progress event (“38% — scoring matches”) and every “action card” (template created, invite sent) lands in the UI in real time. The UI is a five-stage stepper with file-upload widgets, image-upload widgets, and a field-mapping confirmation widget that lets users override the agent’s guesses inline.
Challenges it solves
Onboarding is the leakiest part of the funnel. Every minute a new user spends figuring out how to map their CSV is a minute they’re closer to closing the tab. The agent collapses what used to be a multi-day services engagement into a single conversational session and runs it on session one. Auto-activation via migration means every new tenant gets the agent enabled the moment they sign up — no admin step, no toggle.
Field-matching is fundamentally a quality problem, not a speed problem. A naive “ask the LLM to map this CSV to this schema” prompt drops the worst matches and the best matches into the same answer with no confidence signal. Ember’s pipeline is three deliberate stages: a pairwise scoring pass (Claude Sonnet 4.6 rating each (csv_field → db_field) candidate on similarity), then a Hungarian-algorithm assignment (purely algorithmic — optimal bipartite matching with a small data-type bonus), then a validation sweep that flags duplicates, low confidence, and required-field gaps. The CSV-field-to-DB-field matrix gets pre-trimmed to the top eight candidates per column, which cuts a 19,158-pair scoring problem down to ~824 pairs — much cheaper, no quality loss. Per CSV: 3–5 Claude calls total, batched in groups of 20 fields to dodge max-token truncation.
Large payloads can’t ride in Claude’s text response. A 100+ column mapping serialized into a Claude text completion blows the 4,096-token output cap. The agent pushes mapping payloads directly to the NDJSON stream as a side channel — Claude’s text response stays small, the UI gets the full payload, and tool messages don’t bloat the conversation context.
Real Claude usage breaks in production. The agent doesn’t. Five retries with exponential backoff capped at 120 seconds handle the Anthropic 529 (“overloaded”) error that drops about 1 in every 200 calls under load. The retry wrapper is its own helper (createMessageWithRetry) so every Claude call in the agent is hardened by default.
Agent-driven saves race with the client. Early versions of the flow had Claude calling confirm_field_mapping after the user confirmed in the UI — which meant two parties racing to save the template. The current architecture moves template persistence to the client (it calls a confirmOnboardingMapping() server action directly), and the agent receives a TEMPLATE_CONFIRMED signal and skips the tool call. The deprecated tool is still in the registry with an explicit comment in its description: “[DEPRECATED — do not call this tool. Field mappings are now saved directly by the client. When you receive TEMPLATE_CONFIRMED, the template has already been created.]” — so Claude reads the comment and stays out of the way.
Discovery without context. A new supplier has nothing in the system on first signup. The agent doesn’t ask 20 questions to learn the company; it asks for one URL, fires Firecrawl with a scroll action and a 1500ms wait, and pulls a structured profile out of the homepage in one round-trip. The supplier confirms or corrects rather than authoring from scratch.
Why it matters
Every line item in this thing maps back to a dollar:
- Bounce reduction. PIM onboarding gets abandoned because it’s tedious. A conversational, agent-driven session that ends with a usable product in 15 minutes converts users that a setup wizard would lose.
- Services capacity recovered. Each onboarding the agent runs is one a services engineer doesn’t have to run. At industrial-PIM contract values, that’s six-figure annual savings before any quality improvement.
- Cleaner first-data ingestion. The three-stage pipeline catches mis-mappings before they pollute production data. Pollution is expensive — every downstream system that consumed the bad row eventually has to be reconciled.
- Free-tier unlock. Auto-activation means the agent is a free-tier feature. The paid tier starts where the agent ends. The onboarding work itself sells the rest of the platform.
Key metrics for success
Everything below is instrumented in skill_run_logs (tool_calls, total_tokens, cost_usd, started_at, completed_at) — no extra plumbing required to compute.
- Completion rate — sessions where
mark_onboarding_completefires, divided by sessions started. - Time-to-complete —
completed_at - started_at. Target was 15 minutes; the design budget is 20. - Stage drop-off — which of the six stages a session ends on. Tells you where to invest design or prompt iteration.
- Field-mapping override rate — percentage of field assignments the user manually changed in the confirm widget. Low override rate = the pipeline’s confidence is calibrated; high override rate = a prompt or candidate-selection bug.
- Retry rate on Claude calls — count of 529s per session. Low number = healthy; high number = move to a fallback model.
- Cost per onboarding — sum of token cost across all tool calls per session. Stays under $0.30 in steady state.
Why this is successful
Three reasons it works where a setup wizard wouldn’t:
Conversational matches the user’s mental model. Onboarding to a new product feels like a conversation with the team that built it. The agent IS that team. Users describe their CSV the way they’d describe it in Slack, not the way a form would force them to.
The handoff to humans is explicit, not awkward. If Firecrawl can’t extract a company profile, the agent says so and asks. If the field mapping is uncertain, the confidence scores show up in the UI and the user can override before the template is saved. The agent doesn’t pretend it always knows.
Every architectural decision is reversible. Skill versioning means the prompt is editable without a deploy. Tool definitions live in a shared registry so a swap is local. The deprecated-tool comment means Claude reads the architecture’s history in real time. Nothing is welded; everything is parameterized.
That’s the bet: every other PIM treats onboarding as a problem to outsource to services. Ember treats it as the most important software it ships.