A marketplace, a workforce, a 45-tool registry, and the substrate that makes shipping a new agent take a week.
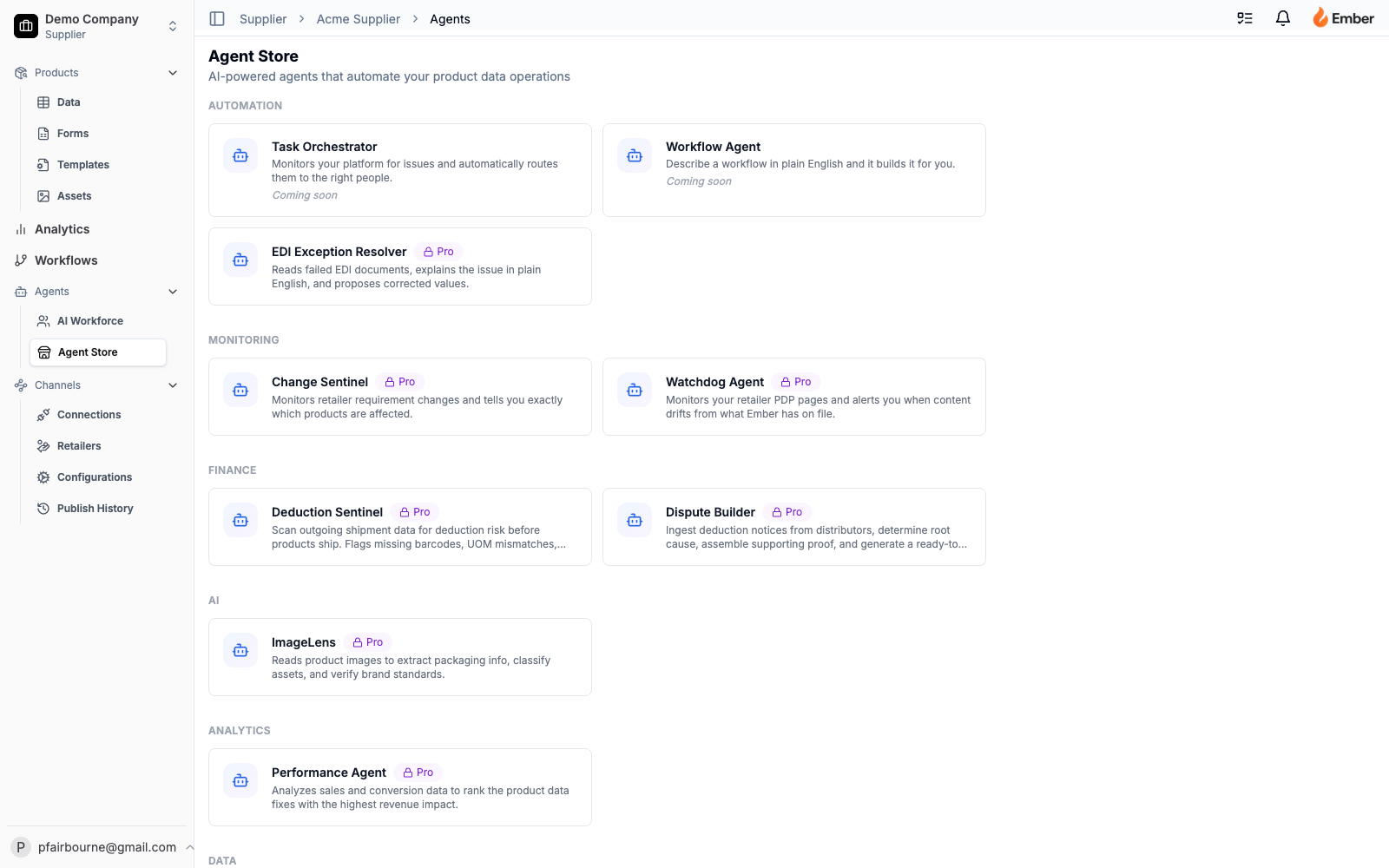
The substrate that makes every Ember agent composable. Agent Store browses 14 agent definitions across 7 categories with free/paid tiers; AI Workforce surfaces the activated agents with run history; a per-company activation table gates paid agents; 45 production-ready tools live in a shared registry; skill versioning lets prompts and tool sets evolve without a redeploy.
The problem
“AI agent” as a category is full of one-off demos. A vendor ships one agent, then ships another, and every agent has its own data layer, its own auth, its own logging, its own deploy story. By agent five, the team is rewriting infrastructure instead of building agents.
The Agent Platform is the answer to that. It’s the part of Ember that lets a sixth agent ship in a week, not a quarter — because the data, the tools, the activation, the gating, the logging, and the UI shell already exist.
What I built
A four-piece substrate that every agent in Ember plugs into:
1. Agent Store (/supplier/[slug]/agents) — the marketplace surface. Reads 14 agents from agent_definitions, filters out the onboarding agent (special-cased — it auto-runs, not browsed), groups by category (data, automation, ai, monitoring, analytics, finance, general). Renders a “Pro” badge on paid-tier agents the company hasn’t activated. Already-activated agents are hidden from the browse view — they live in AI Workforce instead.
2. AI Workforce (/supplier/[slug]/agents/workforce) — the run-history surface. Joins company_agent_activations with the last 50 skill_run_logs and renders each active agent with its last-run timestamp and total run count. The data fetch is one query, returning everything the page needs:
const recentRunsResult = await supabase
.from('skill_run_logs')
.select('id, started_at, completed_at, skills(name, code)')
.eq('company_id', activeCompany.id)
.order('started_at', { ascending: false })
.limit(50)A lastRunMap and a runCountMap get built once on the page render, no per-card queries.
3. The 45-tool registry (server/agent-tools/registry.ts) — a single TOOL_REGISTRY array and a TOOL_MAP for name lookup. Every tool implements the same ToolDefinition shape: name, version, description, input_schema (JSON Schema), and an async execute(input, context). Tools are grouped by phase (Phase 3 Block 1 = data agents; Phase 3 Block 4 = images/PDP; Phase 4 = specialized agents). When an agent ships, it doesn’t write tools; it declares which existing ones it can call.
4. The activation + gating system — company_agent_activations is the per-tenant table that decides which agents a company can see and run. Free agents auto-upsert on signup via a server action using the service role client (RLS on the table restricts user-facing writes; only the application’s admin path can flip activations). Paid agents stay locked behind a “Contact us to upgrade” modal until billing fires.
Layered on top of those four:
Skill versioning — skills + skill_versions tables. Each agent code (onboarding-agent, attribute-mapper, enrichment, etc.) lives in skills; each row in skill_versions carries a versioned system prompt, a SHA-256 prompt_hash for integrity, a tool_permissions array (the whitelist of TOOL_REGISTRY entries the version can call), and Claude parameters (model, max_tokens, temperature, config). The tool_permissions field is the capability whitelist — Claude can’t escalate to tools the version didn’t declare. Versioning lets prompts and tool sets evolve without a deploy: flip is_active to a new row, observe, roll back if needed.
Container pattern — every agent with custom UI ships a *Container.tsx component (OnboardingContainer, AttributeMapperContainer, EnrichmentContainer, DataAnalysisContainer, plus 10 more for the roadmap agents). Containers wrap a generic AgentLaunchPanel that handles skill invocation, polling, and state transitions. The Container’s only job is to render the input form and consume the typed onComplete callback with the run results. Agents without a Container (Workflow Agent, Task Orchestrator) fall through to the default panel and a message: “This agent can be triggered from a Workflow.”
Challenges it solves
The “every agent reinvents the wheel” tax. A new agent built without the platform has to: define its tools, wire them to the database, build a UI shell, instrument logging, implement gating, handle errors. With the platform: pick tools from the registry, write a system prompt, declare permissions, drop in a Container if you need custom UI. Days, not weeks.
Capability containment. When Claude is given access to 45 tools and asked to do anything, it’s an enormous blast radius. skill_versions.tool_permissions is a per-version whitelist — the Onboarding Agent literally cannot call the Enrichment Agent’s write_enriched_value tool, because that tool isn’t in its permissions array. The contract is enforced at invocation time, not via prompt engineering.
Activation auditability. Every row in company_agent_activations is timestamped. When a customer asks “when did we get access to the Vendor Scorecard?” the answer is a SELECT, not a guess. When a paid agent is enabled, it’s an explicit upsert with an activated_at value — no implicit access creep.
Gating that doesn’t require a billing layer to exist. The is_available and tier columns on agent_definitions, combined with company_agent_activations, mean we can stage rollouts (a la “release the agent to internal users only”) and tier features (“free for now, paid in Q2”) without touching the rest of the platform. When billing wires up, the gating logic already exists.
Skill versioning kills the “is the prompt deployed” question. Every prompt is a row. Every change is a new row, hashed, with a timestamp. Rollback is UPDATE skill_versions SET is_active = false WHERE version = N followed by activating the previous row. There’s no scenario where production is running a prompt nobody can trace.
Why it matters
The platform-vs-product framing is the business story:
- Ember without the platform is a couple of nice AI features. Ember with the platform is a marketplace where new specialized agents ship monthly and the substrate makes each one defensible.
- The 45-tool registry is the IP. Building those tools right — with real
execute()functions that touch the database, call external APIs, and handle errors — is most of the work in any agent. Reusing them is the multiplier. - The container pattern means designers and engineers split work cleanly. A new agent’s UI is one new
*Container.tsx. Everything else (auth, RLS, logging, gating, polling) is inherited. - Skill versioning is enterprise-grade by default. “Show me the exact prompt this agent ran on March 12” is a question Ember answers via SELECT. Most agent platforms can’t.
Key metrics
- Agent activation rate. Free agents auto-activate; paid agents require an upgrade. The conversion ratio from “browses the Agent Store” to “activates a paid agent” is the platform’s revenue signal.
- Run frequency per active agent. From
skill_run_logs. Active agents that don’t run aren’t valuable — high activation + low runs means the agent doesn’t fit the user’s workflow. - Tool reuse rate. How many distinct agents call a given tool. High = the tool earned its place in the registry; low = the tool is over-specialized or the agent should ship its own.
- Time-to-ship a new agent. From “we want to build agent X” to “agent X is in the store.” Target: one week. The substrate’s whole purpose is to compress this.
- Skill version churn. How many new
skill_versionsrows per agent per month. High churn = active iteration; zero = the agent is set-and-forget or abandoned. Either is informative.
Why this is hard to copy
Three structural decisions that lock in the moat:
RLS + service-role split on activations. Users can read their company_agent_activations rows but can’t write them; only the application’s admin path (service-role client) can flip activation. Prevents accidental or malicious auto-activation of paid features. Reads stay fast; writes stay safe.
Tool permissions as RBAC. Every Claude invocation is sandboxed to the tool set its skill version declared. Privilege escalation across agents isn’t a thing — it’s not enforceable via prompt engineering; it’s a database column.
Postgres as the source of truth, not the orchestrator. Skills, versions, activations, and run logs all live in Postgres. Inngest does execution. The application owns the policy. The split keeps each layer doing what it’s good at.
This is the part of Ember that says “we’ll be shipping new agents on this platform forever, and the substrate’s already built.”